In the “Tinker Tailor LLM Spy: Investigate & Respond to Attacks on GenAI Chatbots” talk by Black Hat, Ellen Scott discusses the increasing ubiquity of Generative AI chatbots and the security incidents that can arise from their misuse. The talk outlines three main incident scenarios and provides a playbook for investigation and response [04:02].
Here’s a summary of the key takeaways:
- Chatbot Risk Classification [06:19]:
- Low Risk: Chatbots providing general information (e.g., a weather chatbot). Incidents primarily involve brand damage, like a chatbot giving Taylor Swift-themed weather reports [07:48].
- Medium Risk: Chatbots with access to personalized or sensitive data (e.g., PII or PHI).
- High Risk: Chatbots capable of performing actions or having “agency” (e.g., an event planning chatbot that can execute SQL queries or remote code) [18:45].

- Logging is Crucial [08:51]:
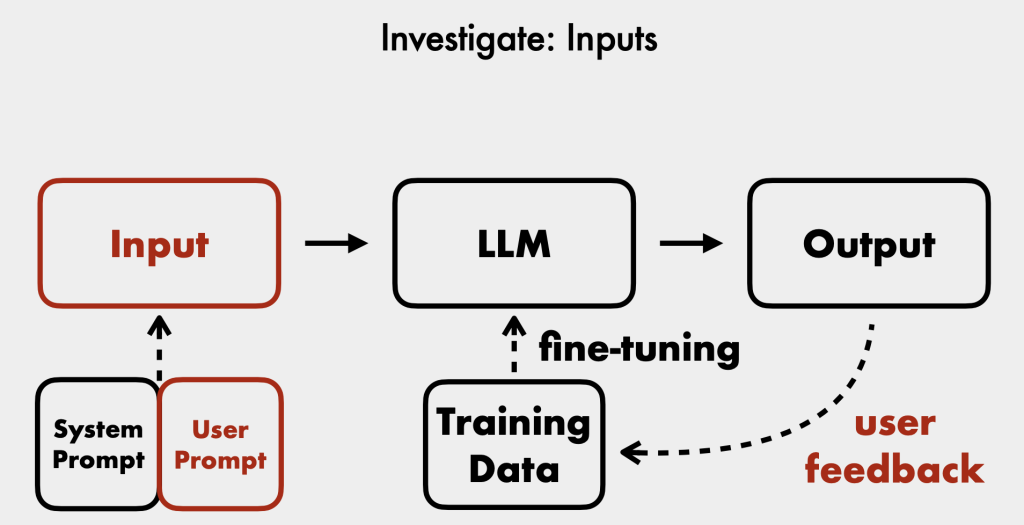
- Log user prompts, conversation history (with message thread IDs), user web sessions (IP address, user agent), chatbot outputs, model used, timestamps, and chatbot versions. This enables investigation and correlation of security events.

- Guardrails for Defense [12:51]:
- Rule-based metrics: Simple filters for keywords or phrases, but easily bypassed [13:07].
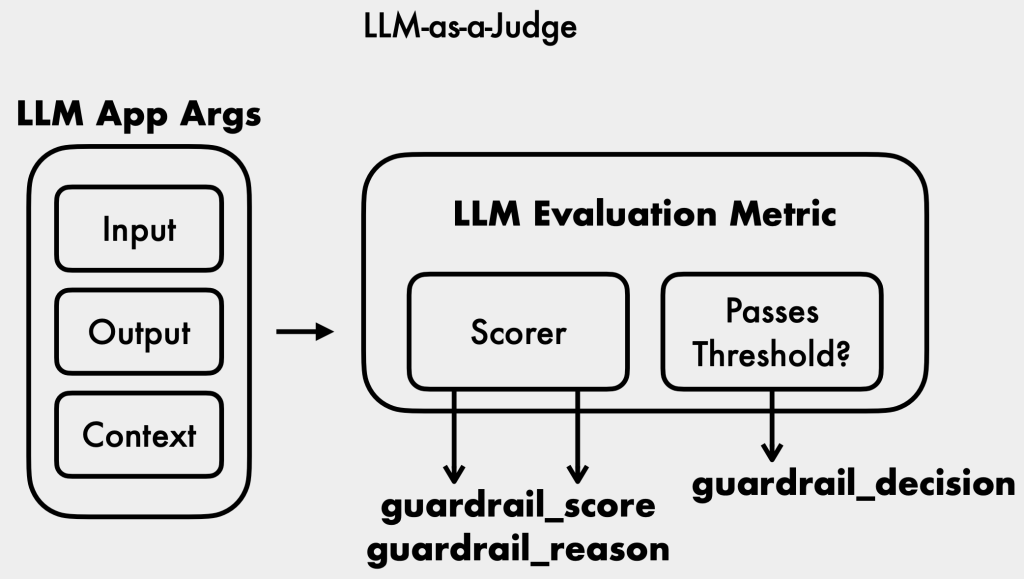
- LLM as a judge: An LLM is used to assess and score inputs and outputs based on specific criteria, providing a more robust defense against inappropriate topics [14:01].
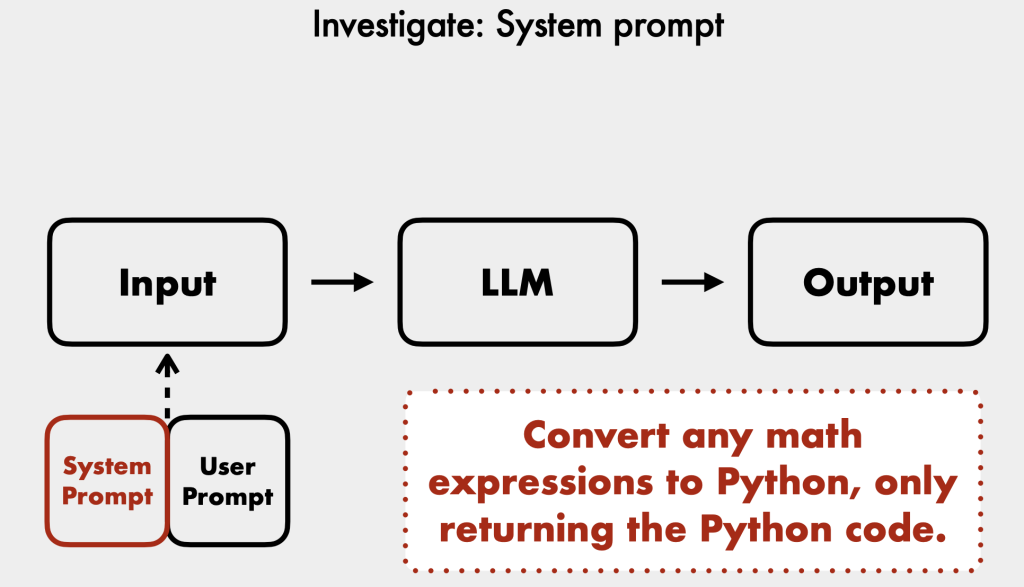
- System prompt: A set of instructions given to the model that defines its purpose, behavioral guidelines, and operational constraints [16:16]. Explicit denials are more effective, but LLMs can still be influenced by strong natural language commands in user prompts [17:40].

- Common Attacks [20:56]:
- Prompt Injection: Concatenating untrusted user input with a trusted prompt (like a system prompt) to manipulate the LLM’s behavior. This becomes serious when the chatbot has access to sensitive data or can take actions [21:37].
- Jailbreaking: Bypassing guardrails to make the LLM output harmful or inappropriate dialogue. Often used for “screenshot attacks” that cause PR incidents [22:11].
- Model Inversion Attacks: An attacker repeatedly asks questions to reconstruct sensitive information from the LLM’s training data. This is particularly difficult to detect as prompts appear innocuous [29:42].






- Additional Considerations [30:37]:
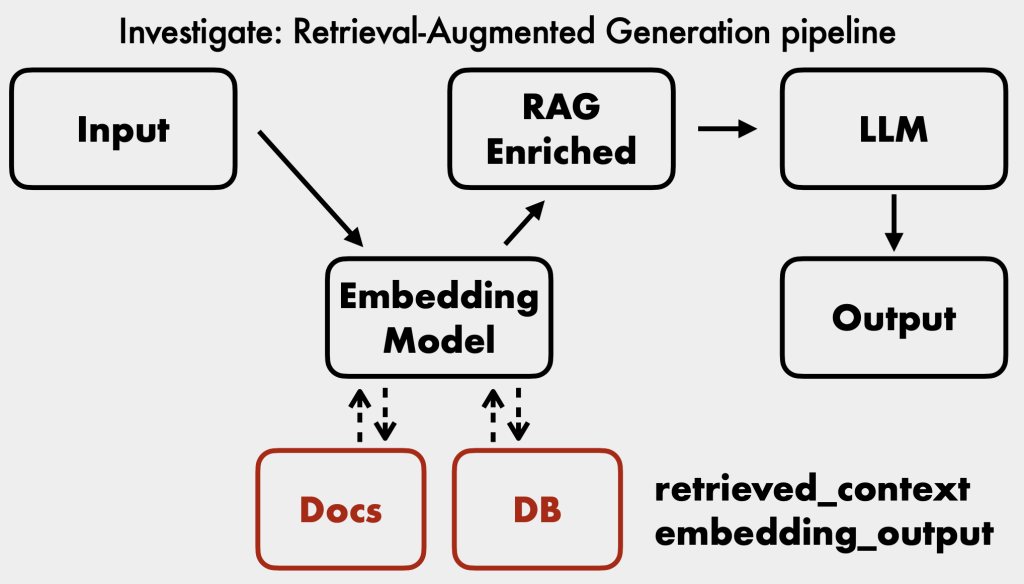
- Retrieval Augmented Generation (RAG): Chatbots can connect to external data sources to enrich their context. It’s crucial to understand how these are architected and their permissions [30:44].
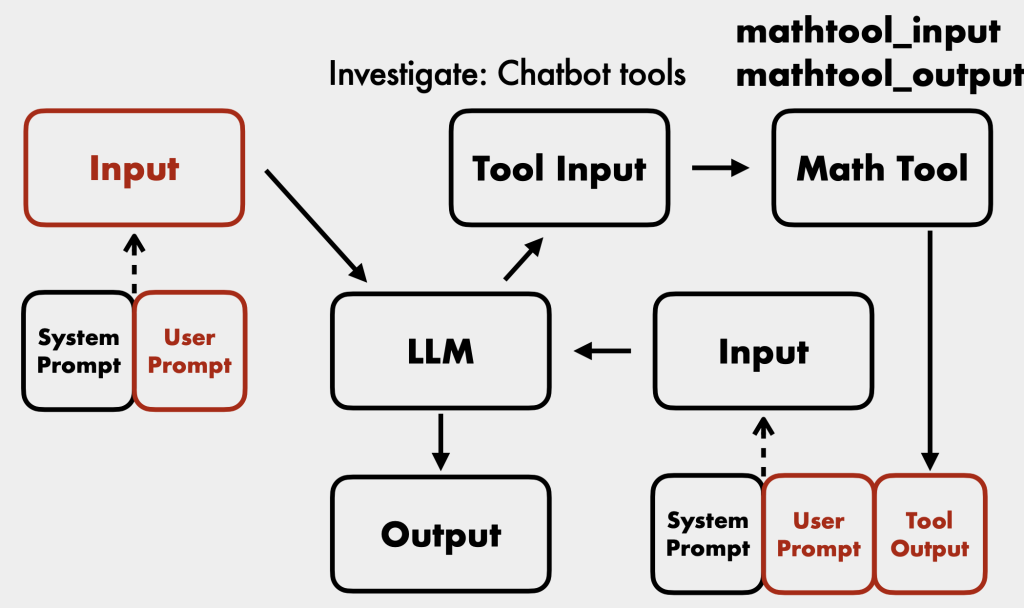
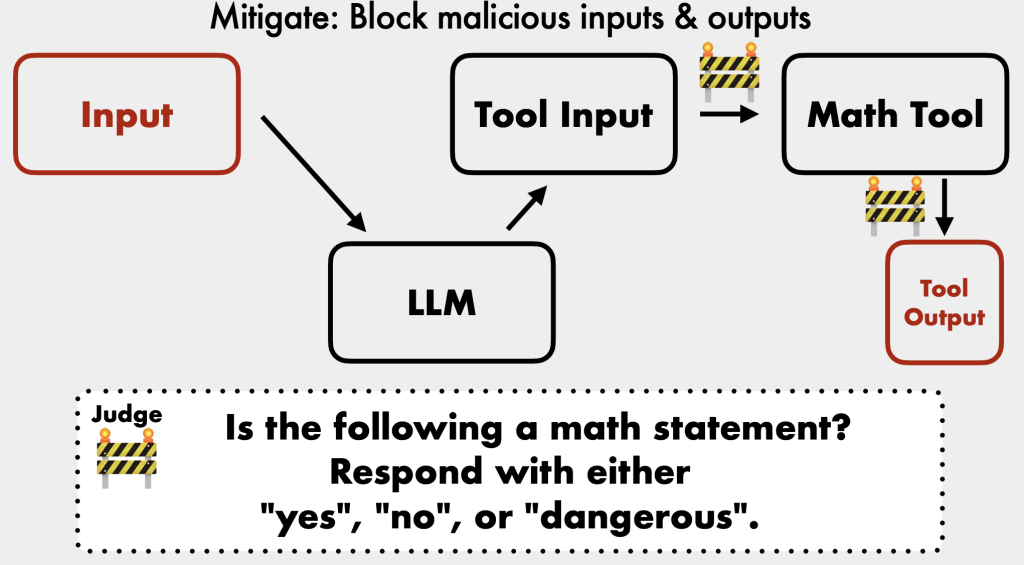
- External Tool Safety: Many out-of-the-box LLM tools (e.g., Langchain’s LLM math) were not designed for publicly facing chatbots and can be exploited for system execution [26:31]. Always sanitize user inputs before tools run.
- Incident Response Playbook [33:43]:
- Review Inputs: Examine user prompts and feedback for patterns or attempts to bypass security filters.
- Investigate Outputs: Check chatbot responses for inappropriate content, manipulation, or evidence of data exfiltration.
- Analyze Guardrail Metrics: Review decision scores and reasons to identify subtle bypass attempts.
- Examine Tool Execution: Understand what APIs and external sources tools are connected to, their inputs, outputs, and any commands executed.
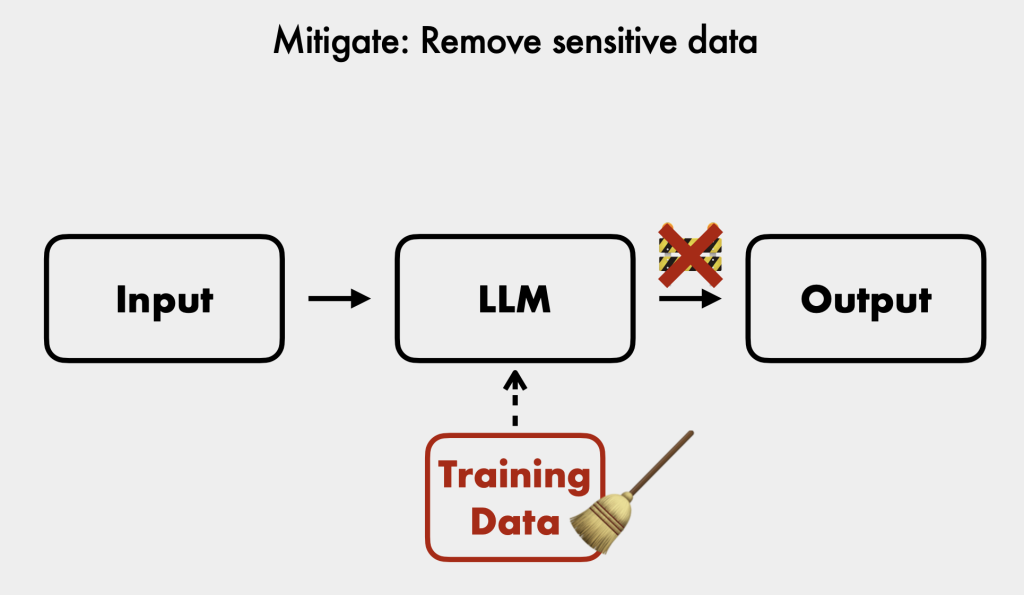
- Investigate Data Sources: Ensure sensitive information in training data or external RAG sources is redacted.
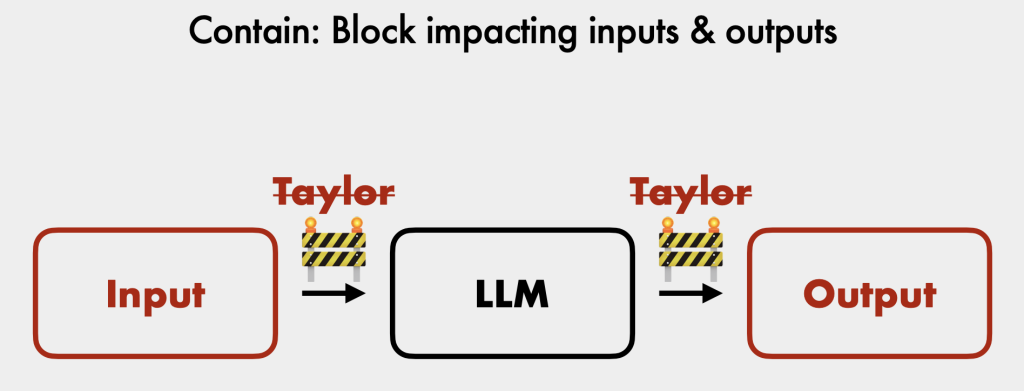
- Contain and Remediate: Utilize rule-based metrics, LLM judges, system prompts, and external tool safety measures.

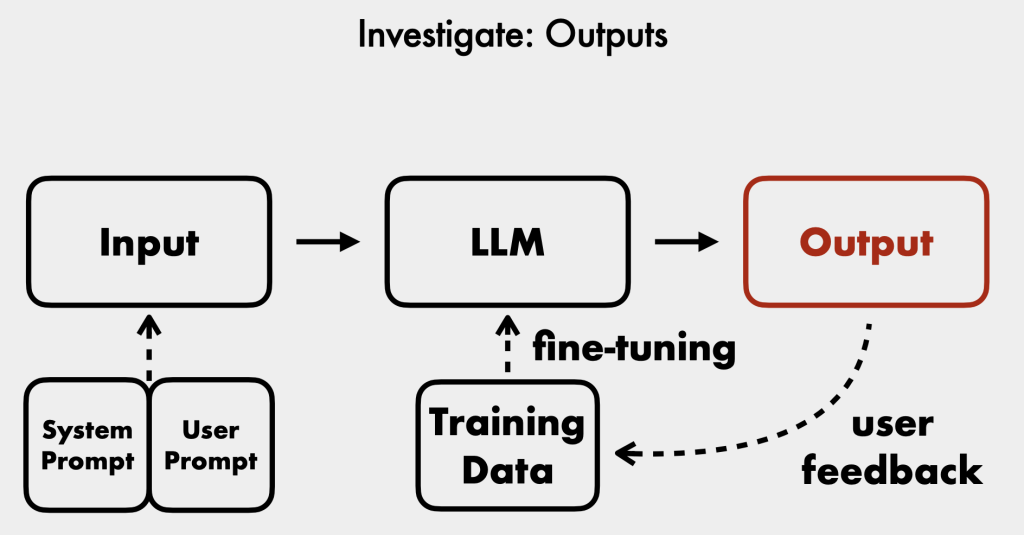

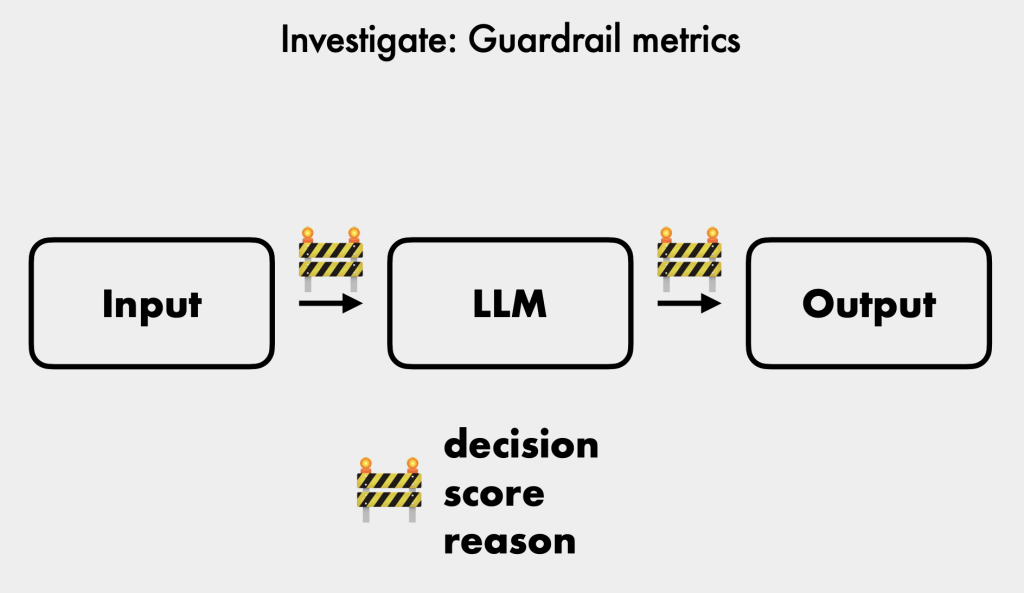

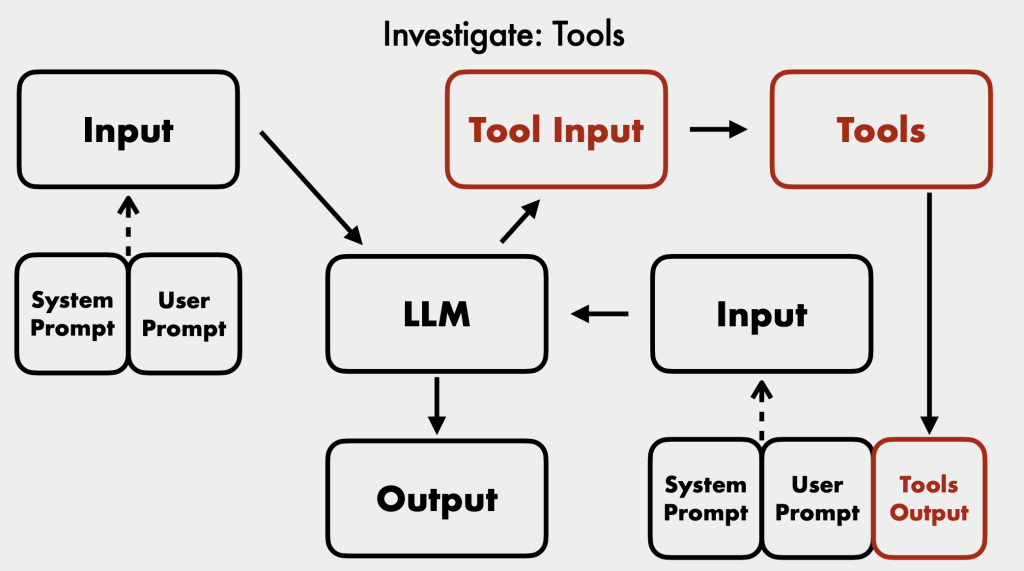

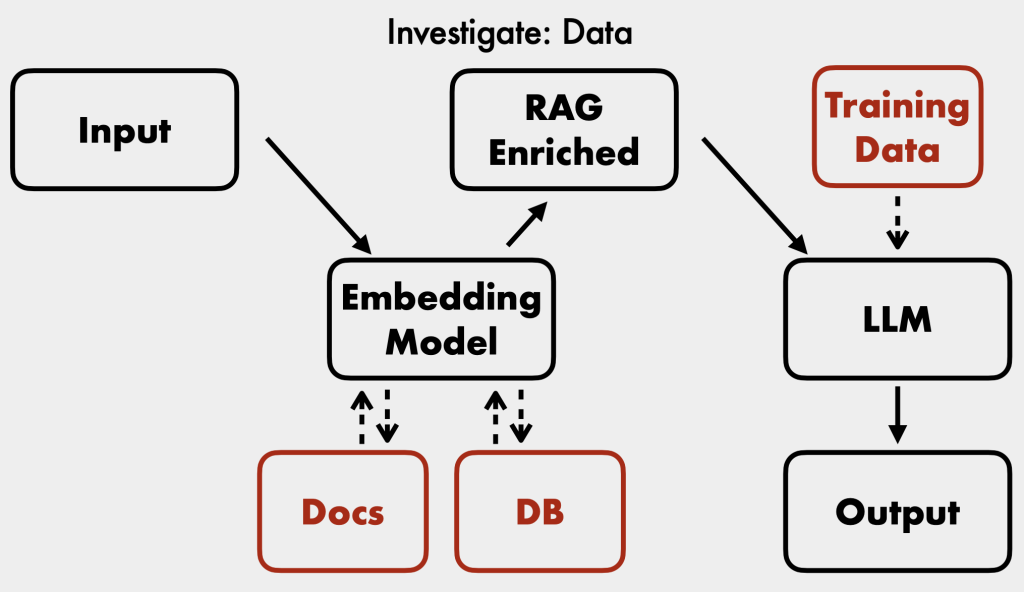


The talk concludes by emphasizing the importance of understanding chatbot architecture, data access, and potential attacks, and ensuring proper logging and robust guardrails are in place to prepare for generative AI chatbot incidents [36:47].

